基础
编辑教程基础
对于大数据,我们要考虑的问题有很多,首先海量数据如何收集(如 Flume),然后对于收集到的数据如何存储(典型的分布式文件系统 HDFS、分布式数据库 HBase、NoSQL 数据库 Redis),其次存储的数据不是存起来就没事了,要通过计算从中获取有用的信息,这就涉及到计算模型(典型的离线计算 MapReduce、流式实时计算Storm、Spark),或者要从数据中挖掘信息,还需要相应的机器学习算法。在这些之上,还有一些各种各样的查询分析数据的工具(如 Hive、Pig 等)。除此之外,要构建分布式应用还需要一些工具,比如分布式协调服务 Zookeeper 等等。
这里,我们讲到的是消息系统,Kafka 专为分布式高吞吐量系统而设计,其他消息传递系统相比,Kafka 具有更好的吞吐量,内置分区,复制和固有的容错能力,这使得它非常适合大规模消息处理应用程序。
消息系统
首先,我们理解一下什么是消息系统:消息系统负责将数据从一个应用程序传输到另外一个应用程序,使得应用程序可以专注于处理逻辑,而不用过多的考虑如何将消息共享出去。
分布式消息系统基于可靠消息队列的方式,消息在应用程序和消息系统之间异步排队。
实际上,消息系统有两种消息传递模式:一种是点对点,另外一种是基于发布-订阅(publish-subscribe)的消息系统。
点对点的消息系统
在点对点的消息系统中,消息保留在队列中,一个或者多个消费者可以消耗队列中的消息,但是消息最多只能被一个消费者消费,一旦有一个消费者将其消费掉,消息就从该队列中消失。
这里要注意:多个消费者可以同时工作,但是最终能拿到该消息的只有其中一个。
最典型的例子就是订单处理系统,多个订单处理器可以同时工作,但是对于一个特定的订单,只有其中一个订单处理器可以拿到该订单进行处理。
发布-订阅消息系统
在发布 - 订阅系统中,消息被保留在主题中。
与点对点系统不同,消费者可以订阅一个或多个主题并使用该主题中的所有消息。
在发布 - 订阅系统中,消息生产者称为发布者,消息使用者称为订阅者。
一个现实生活的例子是Dish电视,它发布不同的渠道,如运动,电影,音乐等,任何人都可以订阅自己的频道集,并获得他们订阅的频道时可用。
Apache Kafka 简介
Kafka是一个分布式、分区、复制的提交日志服务。
Apache Kafka 是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使你能够将消息从一个端点传递到另一个端点。 Kafka 适合离线和在线消息消费。 Kafka 消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka 构建在 ZooKeeper 同步服务之上。 它与 Apache Storm 和 Spark 非常好地集成,用于实时流式数据分析。
Kafka 是一个分布式消息队列,具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。一般在架构设计中起到解耦、削峰、异步处理的作用。
关键术语:
- 生产者和消费者(producer和consumer):消息的发送者叫 Producer,消息的使用者和接受者是 Consumer,生产者将数据保存到 Kafka 集群中,消费者从中获取消息进行业务的处理。
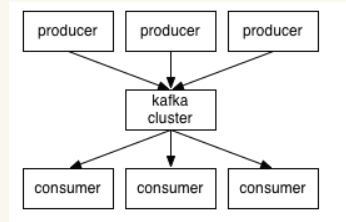
broker:Kafka 集群中有很多台 Server,其中每一台 Server 都可以存储消息,将每一台 Server 称为一个 kafka 实例,也叫做 broker。
主题(topic):一个 topic 里保存的是同一类消息,相当于对消息的分类,每个 producer 将消息发送到 kafka 中,都需要指明要存的 topic 是哪个,也就是指明这个消息属于哪一类。
分区(partition):每个 topic 都可以分成多个 partition,每个 partition 在存储层面是 append log 文件。任何发布到此 partition 的消息都会被直接追加到 log 文件的尾部。为什么要进行分区呢?最根本的原因就是:kafka基于文件进行存储,当文件内容大到一定程度时,很容易达到单个磁盘的上限,因此,采用分区的办法,一个分区对应一个文件,这样就可以将数据分别存储到不同的server上去,另外这样做也可以负载均衡,容纳更多的消费者。
偏移量(Offset):一个分区对应一个磁盘上的文件,而消息在文件中的位置就称为 offset(偏移量),offset 为一个 long 型数字,它可以唯一标记一条消息。由于kafka 并没有提供其他额外的索引机制来存储 offset,文件只能顺序的读写,所以在kafka中几乎不允许对消息进行“随机读写”。
综上,我们总结一下 Kafka 的几个要点:
kafka 是一个基于发布-订阅的分布式消息系统(消息队列)
Kafka 面向大数据,消息保存在主题中,而每个 topic 有分为多个分区
kafak 的消息数据保存在磁盘,每个 partition 对应磁盘上的一个文件,消息写入就是简单的文件追加,文件可以在集群内复制备份以防丢失
即使消息被消费,kafka 也不会立即删除该消息,可以通过配置使得过一段时间后自动删除以释放磁盘空间
kafka依赖分布式协调服务Zookeeper,适合离线/在线信息的消费,与storm和saprk等实时流式数据分析常常结合使用
Apache Kafka基本原理
通过之前的介绍,我们对 kafka 有了一个简单的理解,它的设计初衷是建立一个统一的信息收集平台,使其可以做到对信息的实时反馈。Kafka is a distributed,partitioned,replicated commit logservice。接下来我们着重从几个方面分析其基本原理。
分布式和分区(distributed、partitioned)
我们说 kafka 是一个分布式消息系统,所谓的分布式,实际上我们已经大致了解。消息保存在 Topic 中,而为了能够实现大数据的存储,一个 topic 划分为多个分区,每个分区对应一个文件,可以分别存储到不同的机器上,以实现分布式的集群存储。另外,每个 partition 可以有一定的副本,备份到多台机器上,以提高可用性。
总结起来就是:一个 topic 对应的多个 partition 分散存储到集群中的多个 broker 上,存储方式是一个 partition 对应一个文件,每个 broker 负责存储在自己机器上的 partition 中的消息读写。
副本(replicated )
kafka 还可以配置 partitions 需要备份的个数(replicas),每个 partition 将会被备份到多台机器上,以提高可用性,备份的数量可以通过配置文件指定。
这种冗余备份的方式在分布式系统中是很常见的,那么既然有副本,就涉及到对同一个文件的多个备份如何进行管理和调度。kafka 采取的方案是:每个 partition 选举一个 server 作为“leader”,由 leader 负责所有对该分区的读写,其他 server 作为 follower 只需要简单的与 leader 同步,保持跟进即可。如果原来的 leader 失效,会重新选举由其他的 follower 来成为新的 leader。
至于如何选取 leader,实际上如果我们了解 ZooKeeper,就会发现其实这正是 Zookeeper 所擅长的,Kafka 使用 ZK 在 Broker 中选出一个 Controller,用于 Partition 分配和 Leader 选举。
另外,这里我们可以看到,实际上作为 leader 的 server 承担了该分区所有的读写请求,因此其压力是比较大的,从整体考虑,从多少个 partition 就意味着会有多少个leader,kafka 会将 leader 分散到不同的 broker 上,确保整体的负载均衡。
整体数据流程
Kafka 的总体数据流满足下图,该图可以说是概括了整个 kafka 的基本原理。
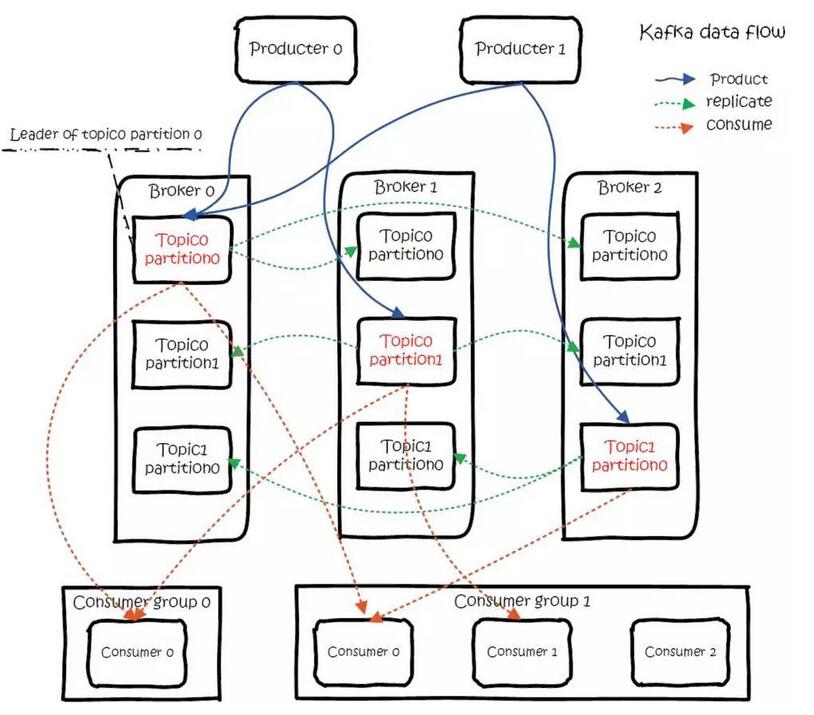
数据生产过程(Produce)
对于生产者要写入的一条记录,可以指定四个参数:分别是 topic、partition、key 和 value,其中 topic 和 value(要写入的数据)是必须要指定的,而 key 和 partition 是可选的。
对于一条记录,先对其进行序列化,然后按照 Topic 和 Partition,放进对应的发送队列中。如果 Partition 没填,那么情况会是这样的:a、Key 有填。按照 Key 进行哈希,相同 Key 去一个 Partition。b、Key 没填。Round-Robin 来选 Partition。
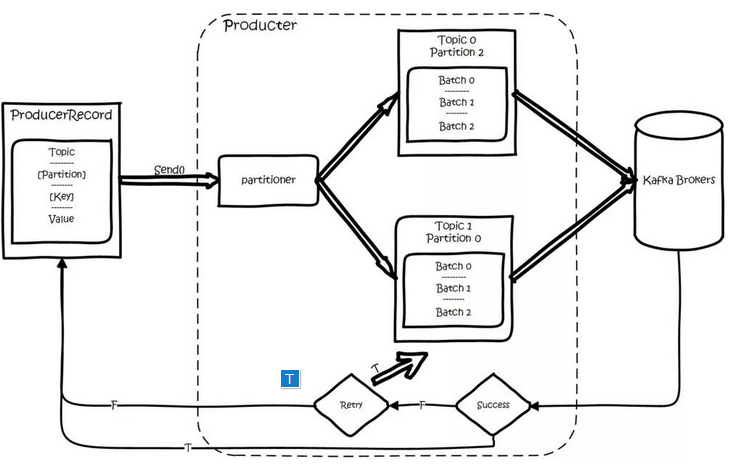
producer 将会和Topic下所有 partition leader 保持 socket 连接,消息由 producer 直接通过socket发送到 broker。其中 partition leader 的位置(host:port)注册在zookeeper中,producer 作为 zookeeper client,已经注册了 watch 用来监听 partition leader 的变更事件,因此,可以准确的知道谁是当前的 leader。
producer 端采用异步发送:将多条消息暂且在客户端 buffer 起来,并将他们批量的发送到 broker,小数据 IO 太多,会拖慢整体的网络延迟,批量延迟发送事实上提升了网络效率。
数据消费过程(Consume)
对于消费者,不是以单独的形式存在的,每一个消费者属于一个 consumer group,一个 group 包含多个 consumer。特别需要注意的是:订阅 Topic 是以一个消费组来订阅的,发送到 Topic 的消息,只会被订阅此 Topic 的每个 group 中的一个 consumer 消费。
如果所有的 Consumer 都具有相同的 group,那么就像是一个点对点的消息系统;如果每个 consumer 都具有不同的 group,那么消息会广播给所有的消费者。
具体说来,这实际上市根据 partition 来分的,一个 Partition,只能被消费组里的一个消费者消费,但是可以同时被多个消费组消费,消费组里的每个消费者是关联到一个 partition 的,因此有这样的说法:对于一个 topic,同一个 group 中不能有多于 partitions 个数的 consumer 同时消费,否则将意味着某些 consumer 将无法得到消息。
同一个消费组的两个消费者不会同时消费一个 partition。

在 kafka 中,采用了 pull 方式,即 consumer 在和 broker 建立连接之后,主动去 pull(或者说 fetch )消息,首先 consumer 端可以根据自己的消费能力适时的去fetch消息并处理,且可以控制消息消费的进度(offset)。
partition中的消息只有一个consumer在消费,且不存在消息状态的控制,也没有复杂的消息确认机制,可见 kafka broker 端是相当轻量级的。
当消息被 consumer 接收之后,需要保存 Offset 记录消费到哪,以前保存在 ZK 中,由于 ZK 的写性能不好,以前的解决方法都是 Consumer 每隔一分钟上报一次,在 0.10 版本后,Kafka 把这个 Offset 的保存,从 ZK 中剥离,保存在一个名叫 consumeroffsets topic 的 Topic 中,由此可见,consumer客户端也很轻量级。
消息传送机制
Kafka 支持 3 种消息投递语义,在业务中,常常都是使用 At least once 的模型。
| At most once: | 最多一次,消息可能会丢失,但不会重复。 |
|---|---|
| At least once: | 最少一次,消息不会丢失,可能会重复。 |
| Exactly once: | 只且一次,消息不丢失不重复,只且消费一次。 |

选择支付方式:


备注:
转账时请填写正确的金额和备注信息,到账由人工处理,可能需要较长时间